I talked a series of Artificial Neural Network (ANN) tutorial last year for a workshop (here), where I showed the very basics. But there are more people asking me some details, which I will cover some of them this week. Hope this will be useful to you.
How to select the parameters
We talked about the hidden neurons in the hidden layer, you may ask 'How do we select the number of neurons?' The way I select the number of neurons in the hidden layer is the 10 fold cross-validation. This is a very common way in machine learning community to find good parameters, it works as shown in the following figure.
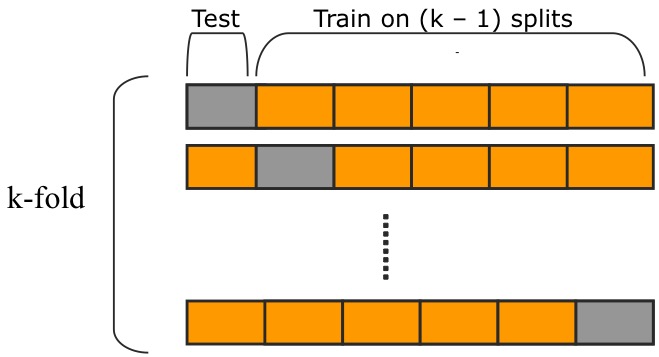
In k-fold cross-validation, the original sample is randomly partitioned into k subsamples. Of the k subsamples, a single subsample is retained as the validation data for testing the model, and the remaining k − 1 subsamples are used as training data. The cross-validation process is then repeated k times (the folds), with each of the k subsamples used exactly once as the validation data. The k results from the folds then can be averaged (or otherwise combined) to produce a single estimation.
Therefore, the 10 fold cross-validation means I split the data into 10 subgroups, and use 9 of them training, and the other 1 to test the result. You can also use this method for other parameters.
There are also other ways to select the parameters, like grid-search and so on. I will not talk here, since I like to use 10 fold cross-validation most of the time.
When to stop training
When training a neural network, we will do many iterations to update the weights. But when do we decide to stop? Let me show you the following figure, and then you will know when to stop.
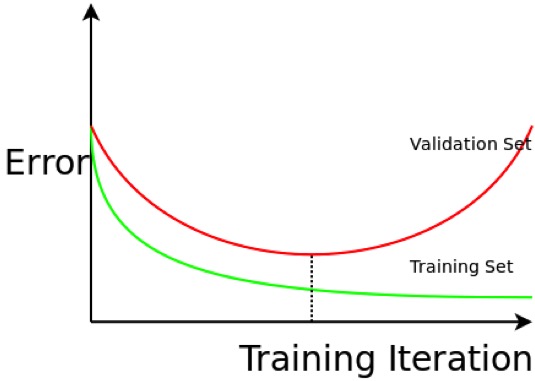
The green curve is the training error, which is the error that we get when we run the trained model back on the training data. The red curve is the validation error, which is the error when we get when we run the trained model on a set of data that it has previously never been exposed to (this is also why this data is called validation data, since it is not used in training, and we keep it for validation purposes). We can see that the green training error is constantly decreasing, but at certain point, the decreasing validation error starts to increase. This usually happens when the model starts overfitting the data, which means that the model is excessively complex, that it is too flexible, it starts to model the noise instead of the hidden patterns. The following is an example (figure from Wikipedia).
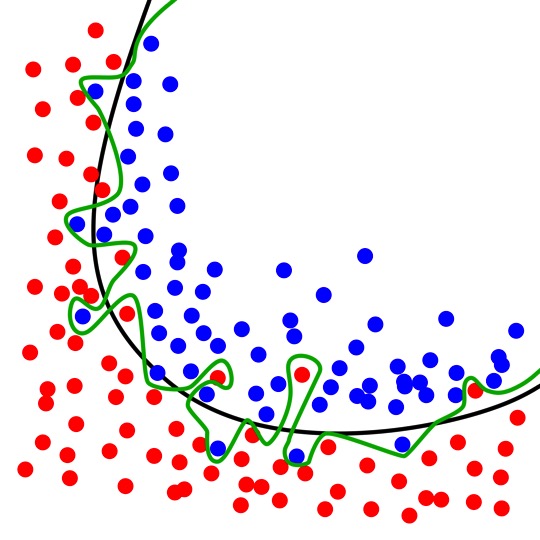
We can build two models to separate the green and blue dots: one model is the black line, and the other is the green curve. We can see the green curve fits the data really well, it separates the green and blue dots without any mistake! The error associated with it is zero! But which model do you think is a better model? Of course, most of us will choose the black model (if you choose the green model, I don't know what to say ...). Even though the black model made some wrong decisions for some training data points, but it will perform better than the green model when applied to new data. The green model fits too much noise, and it becomes so wiggly. If we keep a validation dataset that never used in training the model, we will find that the green model will make more wrong decisions, this will show on the validation error. Therefore, we should stop at the point where we can see a trend the red validation error starts to take off, showing as the black dotted line in the previous figure.
More on learning rate
We didn't talk too much about the gradient descent method before, but you can check out this awesome blog to get more sense - Single-Layer Neural Networks and Gradient Descent. But we do talk about learning rate before, if you still remember, it will control how fast we will learn by control how much we will update the weights. I grab the following figure from the blog, to show you the effect of large and small learning rate.
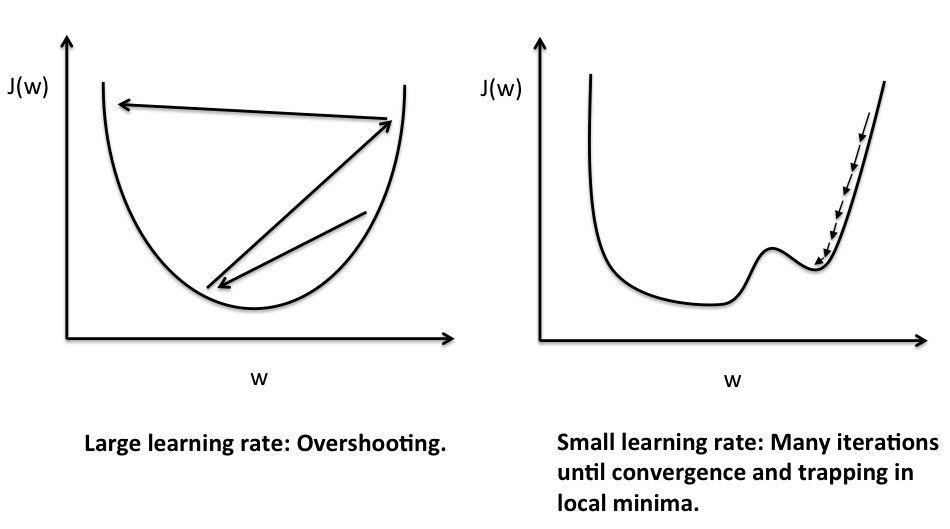
The above figure shows a simple example the effect of using a large and small learning rate. We can see the horizontal axis is our weight, and the vertical axis is the cost function. We can think this as a topographic area in our parameter space (in this case, is the weight). The gradient descent method is to find the steepest direction to our next step by taking the gradient of the topographic area, and to this direction. We want to search for the lowest point in this topographic area (finding the minimum). We can see, if we use a large learning rate, the search will bounce back and forth around the minimum. But if we use a small learning rate, every time we move our search with a small step, it will take very long time to find the lowest point, and sometimes trap our search into a local minima instead of the global minimum (as shown in the figure, and we will talk it more in the next section). We can see the smaller learning rate is more stable. It seems using either small or large learning rate is not sufficient to have a good training scheme, the best way is to use both: an adaptive learning rate. This means that we start with large learning rate, but with more and more iterations, we will shrink the learning rate accordingly. We can think this as at the beginning, we use large learning rate to do a coarse search with large move steps, but when we approach the minimum, we use smaller learning rate to do a fine search in this area.
Momentum
The following figure (from here) shows the complexity of the search for the global minimum. Since most of the times, we will have something not as simple as the previous figures with only one minimum. Instead, we see a very hilly area, that full of different local minima. It is very easy for our search to find a local minimum, and stop searching for a better one. For example, the blue ball stopped in a minimum that is not the global minimum. We can train the algorithm multiple times, and every time start at a different initial location, in the hope that we can start at a place where equal to the global minimum, or at least close to.
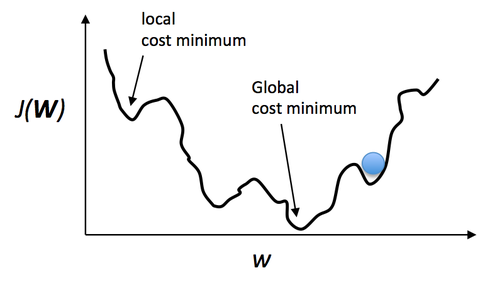
Also, we can also try to make it less likely that the algorithm will get stuck in local minima. Let's look at the above figure, the reason the ball stop in the local minima is due to run out of energy when it rolling down. If we give the ball some weight, when it is rolling down from a higher place, it will likely have a momentum to overcome a small hill on the other side of the local minimum. This idea can be implemented by using a momentum term in the update of the weights. You can check out more explanations on Quora. Now, let's take a rest and look at the following movie to get a sense why the ball did stop at some local traps while having some fun!
I will stop here this week, and there are more details about training a good ANN, but the most important ones are here, and when you read a lot of books or tutorials, you will meet them, and I hope the high-level concept I write here will give you a good start.
Nice information thank you so much
ReplyDeleteMachine Learning Training in Hyderabad
A very useful blog thank you so much.
ReplyDeleteMachine Learning Training in Hyderabad
Thank you for sharing wonderful information with us to get some idea about that content.
ReplyDeletecheck it once through
Machine Learning Training in Chennai | best machine learning institute in chennai | Machine Learning course in chennai
very good informative blog & useful to me thank you...keep posting
ReplyDeleteMachine Learning Training
Nice blog .Thanks for sharing the valuable information.who is looking for "Machine Learning online"
ReplyDeleteThank you.its a nice blog.
ReplyDeleteclick here:
Data Science Online Traning
nice article thanks for sharing
ReplyDeleteData science course in Mumbai
Nice post..
ReplyDeleteaws training in bangalore
artificial intelligence training in bangalore
machine learning training in bangalore
blockchain training in bangalore
iot training in bangalore
artificial intelligence certification
artificial intelligence certification
Thanks for sharing this valuable information and we collected some information from this blog.
ReplyDeleteMachine Learning Training in Gurgaon
I am very happy to visit your blog. This is definitely helpful to me, eagerly waiting for more updates.
ReplyDeleteR Training in Chennai
R Programming Training in Chennai
Machine Learning Course in Chennai
Machine Learning Training in Chennai
Data Science Course in Chennai
Data Science Training in Chennai
Data Science Training in Anna Nagar
Machine Learning Training in Chennai
Thanks for the great post with loads of helpful topics! I look forward to following your blog.
ReplyDeletemachine learning
Thanks for sharing your valuable information and time.
ReplyDeleteMachine Learning Training in Gurgaon
Machine Learning course in Gurgaon
Machine Learning Training institute in Gurgaon
Really nice post thanks for sharing it. Get the best data science training institute in Gurgaon, Noida, Delhi NCR
ReplyDeleteVery informative post thank you. Find the best Blockchain training in Gurgaon
ReplyDeleteVery good post thank you so much. Get the best institute of Data Science with SAS training in Gurgoan.
ReplyDeleteVery informative post I enjoyed reading it. Are you looking for the top Python training institute in Gurgaon
ReplyDeleteReally nice post thanks for sharing it. Find the best Block-chain training in Gurgaon
ReplyDeleteHiiii...Thanks for sharing Great information...Nice post...Keep move on...
ReplyDeleteBlockchain Training in Hyderabad
Thanks for sharing such a great blog Keep posting..
ReplyDeleteMachine Learning Training in Delhi
Thanks for sharing the great post. It means a lot.
ReplyDeleteMachine Learning training in Pallikranai Chennai
Pytorch training in Pallikaranai chennai
Data science training in Pallikaranai
Python Training in Pallikaranai chennai
Deep learning with Pytorch training in Pallikaranai chennai
Bigdata training in Pallikaranai chennai
Machine Learning training in Pallikranai Chennai
ReplyDeletePytorch training in Pallikaranai chennai
Data science training in Pallikaranai
Python Training in Pallikaranai chennai
Deep learning with Pytorch training in Pallikaranai chennai
Bigdata training in Pallikaranai chennai
Thanks for sharing the good post.
ReplyDeleteMachine Learning training in Pallikranai Chennai
Pytorch training in Pallikaranai chennai
Data science training in Pallikaranai
Python Training in Pallikaranai chennai
Deep learning with Pytorch training in Pallikaranai chennai
Bigdata training in Pallikaranai chennai
Enjoyed reading the article above, really explains everything in detail, the article is very interesting and effective. Thank you and good luck for the upcoming articles machine learning training
ReplyDeleteThank you for sharing .The data that you provided in the blog is informative and effective.datascience with python training in bangalore
ReplyDeleteGood Post. I like your blog. Thanks for Sharing
ReplyDeleteMachine Learning Training Institute In Noida
Great Article
ReplyDeleteData Mining Projects
Python Training in Chennai
Project Centers in Chennai
Python Training in Chennai
Thanks for sharing this valuable information and Helpfull Content
ReplyDeleteMachine Learning Training in Noida
Really useful information.
ReplyDeleteMachine Learning Training in Pune
Thank You Very Much For Sharing These Nice Tips.
Hi, Amazing your article you know this article helping for me and everyone and thanks for sharing information https://arun-aiml.blogspot.com/2017/06/welcome-to-aimldl.html?showComment=1577099560528#c4922867245572753492
ReplyDeleteHi, Amazing your article you know this article helping for me and everyone and thanks for sharing information Machine Learning Training institute in Delhi
ReplyDelete
ReplyDeleteI'm too lazy to sign up an account just for comment your article. it's really good and helping dude. thanks!
Machine Learning Training Course in Delhi
Great post. Keep sharing.
ReplyDeleteMachine Learning training in Pallikranai Chennai
Pytorch training in Pallikaranai chennai
Data science training in Pallikaranai
Python Training in Pallikaranai chennai
Deep learning with Pytorch training in Pallikaranai chennai
Bigdata training in Pallikaranai chennai
Mongodb Nosql training in Pallikaranai chennai
Spark with ML training in Pallikaranai chennai
Data science Python training in Pallikaranai
Bigdata Spark training in Pallikaranai chennai
Sql for data science training in Pallikaranai chennai
Sql for data analytics training in Pallikaranai chennai
Sql with ML training in Pallikaranai chennai
APTRON Solutions’s Introduction to Artificial Intelligence course is developed to help candidates decode the artificial intelligence mystery and its applications in businesses.
ReplyDeleteFor More Info: Artificial Intelligence Course in Delhi
ReplyDeleteNice information. Thanks for sharing content and such nice information for me. I hope you will share some more content about. Please keep sharing!
Artificial Intelligence Training in Chennai
Thank you for sharing the article. The data that you provided in the blog is informative and effective.
ReplyDeleteBest data science Online Training Institute
ReplyDeleteNice information. Thanks for sharing content and such nice information for me. I hope you will share some more content about. Please keep sharing!
Artificial Intelligence Training in Chennai
ReplyDeleteNice information. Thanks for sharing content and such nice information for me. I hope you will share some more content about. Please keep sharing!
Best Artificial Intelligence Training in Chennai
Good Post. I like your blog. It is very useful to us. Thanks for Sharing.
ReplyDeleteArtificial Intelligence Course
ReplyDeleteNice information. Thanks for sharing content and such nice information for me. I hope you will share some more content about. Please keep sharing!
artificial intelligence training institutes in chennai
Nice post. Keep sharing with us.
ReplyDeleteMachine Learning training in Pallikranai Chennai
Pytorch training in Pallikaranai chennai
Data science training in Pallikaranai
Python Training in Pallikaranai chennai
Deep learning with Pytorch training in Pallikaranai chennai
Bigdata training in Pallikaranai chennai
Mongodb Nosql training in Pallikaranai chennai
Spark with ML training in Pallikaranai chennai
Data science Python training in Pallikaranai
Bigdata Spark training in Pallikaranai chennai
Sql for data science training in Pallikaranai chennai
Sql for data analytics training in Pallikaranai chennai
Sql with ML training in Pallikaranai chennai
Great post. Thanks for sharing.
ReplyDeleteMachine Learning training in Pallikranai Chennai
Pytorch training in Pallikaranai chennai
Data science training in Pallikaranai
Python Training in Pallikaranai chennai
Deep learning with Pytorch training in Pallikaranai chennai
Bigdata training in Pallikaranai chennai
Mongodb Nosql training in Pallikaranai chennai
Spark with ML training in Pallikaranai chennai
Data science Python training in Pallikaranai
Bigdata Spark training in Pallikaranai chennai
Sql for data science training in Pallikaranai chennai
Sql for data analytics training in Pallikaranai chennai
Sql with ML training in Pallikaranai chennai
It is amazing to visit your site. Thanks for sharing this information, this is useful to me...
ReplyDeleteDocker and Kubernetes Training in Hyderabad
Kubernetes Online Training
Docker Online Training
Really impressed! Everything is very open and very clear clarification of issues. It contains truly facts. Your website is very valuable. Thanks for sharing.
ReplyDeletemachine learning training in hyderabad
artificial intelligence course 360DigiTMG
I am learning data science, this is very good information to learn more about other topics also. i am waiting for more articles by the same author thank you for valuable information
ReplyDeletemachine learning course
python training in bangalore | python online training
ReplyDeleteaws training in Bangalore | aws online training
artificial intelligence training in bangalore | artificial intelligence online training
machine learning training in bangalore | machine learning online training
data science training in bangalore | data science online training
Thanks for sharing the good post.
ReplyDeleteMachine Learning training in Pallikranai Chennai
Pytorch training in Pallikaranai chennai
Data science training in Pallikaranai
Python Training in Pallikaranai chennai
Deep learning with Pytorch training in Pallikaranai chennai
Bigdata training in Pallikaranai chennai
Mongodb Nosql training in Pallikaranai chennai
Spark with ML training in Pallikaranai chennai
Data science Python training in Pallikaranai
Bigdata Spark training in Pallikaranai chennai
Sql for data science training in Pallikaranai chennai
Sql for data analytics training in Pallikaranai chennai
Sql with ML training in Pallikaranai chennai
Great post. I was once checking constantly this weblog and I'm impressed! Extremely useful information specially the closing part :) I maintain such information much. I was previously seeking this particular information for a lengthy time. Many thanks and best of luck.
ReplyDeletecomputer science engineering
bachelor in commerce
bachelor of computer science
best private engineering colleges in india
mba admission 2020
BTech admission
best business schools in india
artificial intelligence online course
Machine Learning & Artificial Intelligence
top engineering colleges in up
Good Post! Thank you so much for sharing this pretty post, it was so good to read and useful to improve my knowledge as updated one, keep blogging.
ReplyDeleteR Programming Training in Bangalore
I just found this blog and have high hopes for it to continue. Keep up the great work, its hard to find good ones. I have added to my favorites. Thank You.artificial intelligence course in noida
ReplyDeleteThanks for sharing an informative blog keep rocking bring more details.I like the helpful info you provide in your articles. I’ll bookmark your weblog and check again here regularly. INice blog,I understood the topic very clearly,And want to study more like thisJava training in Chennai
ReplyDeleteJava Online training in Chennai
Java Course in Chennai
Best JAVA Training Institutes in Chennai
Java training in Bangalore
Java training in Hyderabad
Java Training in Coimbatore
Java Training
Java Online Training
I want to tell you that I am new to weblog and definitely like this blog site. It is very possible that I am going to bookmark your blog. You have amazing stories. Thanks for sharing the best article post.
ReplyDeleteselenium training in chennai
selenium training in chennai
selenium online training in chennai
software testing training in chennai
selenium training in bangalore
selenium training in hyderabad
selenium training in coimbatore
selenium online training
selenium training
Thanks for sharing an informative blog keep rocking bring more details.I like the helpful info you provide in your articles. I’ll bookmark your weblog and check again here regularly. INice blog,I understood the topic very clearly,And want to study more like this information.
ReplyDeleteangular js training in chennai
angular training in chennai
angular js online training in chennai
angular js training in bangalore
angular js training in hyderabad
angular js training in coimbatore
angular js training
angular js online training
ReplyDeleteI am really enjoying reading your well written articles. It looks like you spend a lot of effort and time on your blog. I have bookmarked it and I am looking forward to reading new articles. Keep up the good work.
Azure Training in Chennai
Azure Training in Bangalore
Azure Training in Hyderabad
Azure Training in Pune
Azure Training | microsoft azure certification | Azure Online Training Course
Azure Online Training
This information is helpful to students. Informative blog. Data science course in pune
ReplyDeleteHey, What's up, I'm Shivani. I'm an application developer living in Noida, INDIA. I am a fan of technology. I'm also interested in programming and web development. You can download my app with a click on the link. Best astrology app
ReplyDeleteAstro guru online
Best astrologer
Talk to astrologer
Onlne astrologer
Online pandit
Online astrologer in delhi NCR
Hi.. Thanks for these type of articles.. keep sharing.
ReplyDeletemachine learning training in pallikranai chennai
data science training in pallikaranai
python training in pallikaranai chennai
bigdata training in pallikaranai chennai
spark with ml training in pallikaranai chennai
You always try to sharing such a good information with us.
ReplyDeleteMachine Learning Trainng in Noida
Machine Learning Trainng institute in Noida
Best Selenium Training in Bangalore - KRN Informatix is a leading Selenium Training in Bangalore offering extensive Selenium Training in Automation Testing with real-time projects which fetches you a right job for your carrier.
ReplyDeleteMachine Learning Training Institute in Noida
ReplyDeleteI am very happy to visit your blog. This is definitely helpful to me, eagerly waiting for more updates.
ReplyDeleteAWS Course in Bangalore
AWS Course in Hyderabad
AWS Course in Coimbatore
AWS Course
AWS Certification Course
AWS Certification Training
AWS Online Training
AWS Training
Wonderful Blog! I would Thanks for sharing this wonderful content.its very useful to us.I gained many unknown information, the way you have clearly explained is really fantastic.keep posting such useful information.
ReplyDeleteIELTS Coaching in chennai
German Classes in Chennai
GRE Coaching Classes in Chennai
TOEFL Coaching in Chennai
spoken english classes in chennai | Communication training
Thank you for sharing your article. Great efforts put it to find the list of articles which is very useful.
ReplyDeleteacte chennai
acte complaints
acte reviews
acte trainer complaints
acte trainer reviews
acte velachery reviews complaints
acte tambaram reviews complaints
acte anna nagar reviews complaints
acte porur reviews complaints
acte omr reviews complaints
This comment has been removed by the author.
ReplyDeleteAs we know, Machine Learning is the future of the industries these days, this article helps me to figure out which language I need to learn to pursue the future in this field.
ReplyDeletegood blog! machine learning online training!
ReplyDeleteThis concept is a good way to enhance the knowledge.thanks for sharing..
ReplyDeleteWe are giving all Programming Courses such as You can
Register for a free Demo Sessions
RPA Ui Path Online Training
Best Python Online Training
Online AWS Training
Online Data Science Training
Hadoop Online Training
Thanks for sharing such a nice post. I must suggest your readers to Visit Data science and AI Course in Chennai
ReplyDeleteThanks for the information. This is very nice blog. Keep posting these kind of posts. All the best.
ReplyDeleteDiscovering Top Companies Leveraging Artificial Intelligence/Artificial Intelligence, AI, Sephora
very special. easy to understand…. taking things from root .. stay blessed
ReplyDeleteWe have an excellent IT courses training institute in Hyderabad. We are offering a number of courses that are very trendy in the IT industry. For further information. best machine learning course online!
I have bookmarked your site since this site contains significant data in it. You rock for keeping incredible stuff. I am a lot of appreciative of this site.
ReplyDeletemasters in data science
Thank you for sharing the post,keep blogging
ReplyDeleteBest AWS Online Training
Thank you for taking the time and sharing this information with us. It was indeed very helpful and insightful while being straight forward and to the point.
ReplyDelete<a href="https://nareshit.com/selenium-online-training/“> selenium online training </a>
Thank you for taking the time and sharing this information with us. It was indeed very helpful and insightful while being straight forward and to the point.
ReplyDeletehttps://nareshit.com/selenium-online-training/
reactjs online training
ReplyDeleteselenium online training
ReplyDeleteAutomation/PLC/SCADA Training Institutes in India, Automation/PLC/SCADA Training Courses list which will help you to be a certified PLC Professional. We offers exclusive PLC SCADA Training program with 100% Job Placement. Call @9953489987, 9711287737.
ReplyDeleteOn the off chance that your searching for Online Illinois tag sticker restorations, at that point you have to need to go to the privileged place.
ReplyDeletedata science course delhi
Hi, Thanks for sharing wonderful stuff...
ReplyDeleteMachine Learning Training in Hyderabad
Very Nice Article! Get more on certificate course in machine learning.
ReplyDeleteThis blog is truly amazing we are the leading Weighbridge manufacturers
ReplyDeleteGreat post i must say and thanks for the information. Education is definitely a sticky subject. However, is still among the leading
ReplyDeleteMachine Learning Corporate Training
https://www.analyticspath.com/machine-learning-corporate-training
Phenomenal post.I need to thank you for this enlightening read, I truly value sharing this incredible post.Keep up your work
ReplyDeleteAI Corporate Training
https://www.analyticspath.com/artificial-intelligence-corporate-training
ReplyDeleteReally i found this article more informative, thanks for sharing this article! Also Check here
Machine Learning Corporate Training
https://www.analyticspath.com/machine-learning-corporate-training
Very well written post. Thanks for sharing this, I really appreciate you taking the time to share with everyone. Best Project Management Courses In Hyderabad
ReplyDeleteThanks for the information Keep sharing.
ReplyDeleteMachine Learning training in Pallikranai Chennai
Data science training in Pallikaranai
Python Training in Pallikaranai chennai
Bigdata training in Pallikaranai chennai
Spark with ML training in Pallikaranai chennai
Internet Business Ideas for 2020
ReplyDeleteThanks for the informative article.
ReplyDeleteThis is one of the best resources I have found in quite some time.
Nicely written and great information We are technology/news/smartphone company, If you want to read such useful news then Visit us: https://techmie.com/
This is very informative article. We are technology/news/smartphone company, If you want to read such useful news then
ReplyDeleteVisit us: https://techmie.com/
R Programming Course in Noida
ReplyDeleteIt was great experience after reading this.
ReplyDeletePython Training in Gurgaon
Python Course in Gurgaon
Awesome blog. I enjoyed reading your articles. This is truly a great read for me. I have bookmarked it and I am looking forward to reading new articles. Keep up the good work!
ReplyDeleteMachine Learning Training in Delhi
ReplyDeleteThanks for the detail blog.The blog gives valuable information about what i was searching.I really like the blog post.You may als visit Global tech council to get the best deal.
ReplyDeleteVisit- best artificial intelligence course
Amazing post thanks for sharing such information.
ReplyDeleteArtificial Intelligence (AI) Impact on Mobile App Development
I have read your blog its very attractive and impressive. I like it your blog. 4586
ReplyDeleteMachine Learning Course in Delhi
ReplyDeleteThanks for sharing such useful information Difference Between Artificial Intelligence and Machine learning
ReplyDeleteI have bookmarked your site since this site contains significant data in it. You rock for keeping incredible stuff. I am a lot of appreciative of this site.
ReplyDeletedata science courses in delhi
I'm cheerful I found this blog! Every now and then, understudies need to psychologically the keys of beneficial artistic articles forming. Your information about this great post can turn into a reason for such individuals.
ReplyDeletearttificial intelligence training in aurangabad
I am really appreciative to the holder of this site page who has shared this awesome section at this spot
ReplyDeletedata science courses in delhi
This knowledge.Excellently composed article, if just all bloggers offered a similar degree of substance as you, the web would be a greatly improved spot. If you don't mind keep it up.
ReplyDeletecertification of data science
Thanks for the useful information.keep sharing with us.
ReplyDeleteMachine Learning training in Pallikranai Chennai
Data science training in Pallikaranai
Python Training in Pallikaranai chennai
Bigdata training in Pallikaranai chennai
Spark with ML training in Pallikaranai chennai
Thanks for sharing this Information. Machine Learning Training in Gurgaon
ReplyDeleteIncredible post. We are the provider of Engineering solutions in Delhi and additive manufacturing technologies (Servo planetary, Strainwave gearboxes, AGV, Six axis collaborative, Pic & place gantry robots) provider in India. Specialist engineering solutions service the clients across a range of engineering segments helping improve their engineering efficiency.
ReplyDeleteFor More Information:
Contact Us: Precimotion
Email: precimotionsolution@gmail.com
Website: https://www.precimotion.co/
Phone: 8285021966
ReplyDeleteVery nice blog and articles. I am really very happy to visit your blog. Now I am found which I actually want. I check your blog everyday and try to learn something from your blog. Thank you and waiting for your new post. Also Visit my website.https://www.oddylabs.com/
Thanks for the detailed blog the is informative.It really contain informational content about what the user really search.
ReplyDeleteFor more detail visit-
Machine Learning Certification
Machine Learning Course in Noida
ReplyDeleteThank you for taking the time and sharing this information with us. It was indeed very helpful and insightful while being straight forward and to the point.Online Professional Courses in Bangalore
ReplyDeleteVery Nice Blog!!!
ReplyDeletePlease Have a Look at:
Professional Hackers for Hire
Hire A Hacker
Ethical Hackers for Hire
Legit Hackers for Hire
I read that Post and got it fine and informative. Please share more like that...
ReplyDeletedata science in malaysia
single customer view, Pretty good post. I just stumbled upon your blog and wanted to say that I have really enjoyed reading your blog posts. Any way I'll be subscribing to your feed and I hope you post again soon. Big thanks for the useful info.
ReplyDeletedata warehouse, Very efficiently written information. It will be beneficial to anybody who utilizes it, including me. Keep up the good work. For sure i will check out more posts. This site seems to get a good amount of visitors.
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteThanks for sharing this post. ISO 22301 Certification Kuwait
ReplyDeleteIncredibly conventional blog and articles. I am realy very happy to visit your blog. Directly I am found which I truly need. Thankful to you and keeping it together for your new post.
ReplyDeletedata analytics training in yelahanka
ReplyDeleteFantastic post. And we are eager to read posts like this. thank you very much. Directly I am found which I truly need. please visit our website for more information about Machine Learning and Artificial Intelligence
Machine learning 9 - More on Artificial Neural Network nice blog post!!!
ReplyDeletetop analytics companies
Analytics for Micro Markets
Business Analytics
business data analysis
This is an excellent post I seen thanks to share it. It is really what I wanted to see hope in future you will continue for sharing such a excellent post.
ReplyDeleteInteroperability
This comment has been removed by the author.
ReplyDeleteAll the best for your next blog post, really appreciative work.
ReplyDeletepython developer
Your info is really amazing with impressive content. Excellent blog with an informative concept.
ReplyDeleteHadoop Training Institute
This comment has been removed by the author.
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteNice and very informative blog, glad to learn something through you.
ReplyDeleteartificial intelligence course in noida
This comment has been removed by the author.
ReplyDeleteSuch a very useful information!Thanks for sharing this useful information with us. Really great effort.
ReplyDeleteartificial intelligence course in noida
Amazing blog.Thanks for sharing such excellent information with us. keep sharing...
ReplyDeleteai training in noida
Very good blogger and thanks for sharing useful information.
ReplyDeleteOnline Big Data Hadoop Training Cost
Very nice post thanks for sharing Such a Wonderful Information.
ReplyDeleteIndian Digital Academy is one of the Digital Marketing Institute in Hyderabad
Get 1 Moth Free Services Contact Now 630362 26037
An extraordinary piece that reveals genuinely necessary insight into arising subjects like AI and ML development and its effect on business as there are numerous new subtleties you posted here. Now and then it isn't so natural to assemble a Mobile Application advancement without custom information; here you need legitimate improvement abilities and experienced Top AI ML development company. Be that as it may, the subtleties you notice here would be a lot of accommodating for the Startup program. Here is one more first rate arrangement supplier "X-Byte Enterprise Solutions" who render achievable and solid answers for worldwide customers.
ReplyDeleteKnow more here: Top AI ML development company in USA
Nice article. I liked very much. All the information given by you are really helpful for my research. keep on posting your views.
ReplyDeletedata science courses
Excellence blog! Thanks For Sharing, The information provided by you is really a worthy. I read this blog and I got the more information about
ReplyDeletedata analytics course delhi
Excellence blog! Thanks For Sharing, The information provided by you is really a worthy. I read this blog and I got the more information about
ReplyDeleteai training in noida
Good information you shared. keep posting.
ReplyDeletedata scientist certification
Good information you shared. keep posting.
ReplyDeletedata analytics courses in delhi
Good information you shared. keep posting.
ReplyDeleteai training in noida
Excellent Blog! I would Thanks for sharing this wonderful content. Its very useful to us.I gained many unknown information, the way you have clearly explained is really fantastic.keep posting such useful information.
ReplyDeleteTop Voice recognition softwares provides multi-lingual facilities, voice navigation, and customer analytics. The rapid digital transformation enabled the boom of the Voice recognition market.
Top 10 Voice Recognition Software To Embrace in 2021
Techforce services is a Salesforce Consulting Services in Australia Specialising in delivering end to end Salesforce solutions ,Consulting, Implementation DevOps partners in australia We deliver applications and services more rapidly and reliably, but it’s more than a methodology – it cuts to the very core.Salesforce Data Analytics let us help you become a data driven organisation and ensure your data is working hard for your business This includes implementi
ReplyDeleteTechforce services in Australia
Salesforce Consulting Services in Australia
Salesforce Staff Augmentation in Australia
Salesforce Data Analytics
DevOps Partners in Australia
Managed Projects Salesforce Australia
Nice article. I liked very much. All the information given by you are really helpful for my research. keep on posting your views.
ReplyDeletedata analytics courses in delhi
Nice article. I liked very much. All the information given by you are really helpful for my research. keep on posting your views.
ReplyDeleteai training in noida
"Very Nice Blog!!!
ReplyDeletePlease have a look about "
data science courses in noida
My spouse and I love your blog and find almost all of your posts to be just what I’m looking for. Appreciating the persistence you put into your blog and the detailed information you provide. I found another one blog like you. Actually I was looking for the same information on internet for this and came across your blog. I am impressed by the information that you have on this blog. Thanks once more for all the details.
ReplyDeleteRegards
Akhilesh Vinodiya
PMP Certification Course Training in Aurangabad for Beginners
Good Article published by your company, its very useful content for user's. Thanks for sharing such a nice Post, i must appriciate that you write this article for user's. We are also leading in same profile in Gurgaon, SSDN Technologies offers anyone to learn about Artificial Intelligence Course in Gurgaon from basic to advance level. We are one of the best AI Training Institute in Gurgaon.
ReplyDeleteThanks for Sharing This Article.It is very so much valuable content. I hope these Commenting lists will help to my website
ReplyDeletebest data science course in delhi
Thanks for Sharing This Article.It is very so much valuable content. I hope these Commenting lists will help to my website
ReplyDeletedata scientist course in delhi
Thanks for Sharing This Article.It is very so much valuable content. I hope these Commenting lists will help to my website
ReplyDeleteartificial intelligence course in noida
This is really a great post. Thank you for taking the time to provide us some useful and exclusive information. Online English language tutors
ReplyDeleteThanks for providing it, this is very useful blog post.
ReplyDeleteSSB Interview Preparation | SSB Interview Preparation | NDA Coaching Centre | Senaabhyas Education Centre | Best Defence Coaching in Agra | Amish Das | NDA SSB Interview
Thanks for providing it, this is very useful blog post.
ReplyDeleteSSB Interview Preparation | SSB Interview Preparation | NDA Coaching Centre | Senaabhyas Education Centre | Best Defence Coaching in Agra | Amish Das | NDA SSB Interview
I am really very happy to visit your blog. Directly I am found which I truly need. please visit our website for more information about Machine Learning Company In Australia
ReplyDeleteWas in search for this information from a long time. Thank you for such informative post.
ReplyDeletehttp://www.analyticspath.com/machine-learning-training-in-hyderabad
Find best Python Training In Gurgaon https://www.bestforlearners.com/course/gurgaon/best-python-course-training-institutes-in-gurgaon
ReplyDeletefind best AWS Certification In Gurgaon https://www.bestforlearners.com/course/gurgaon/aws-training-institute-in-gurgaon
ReplyDeletefind best AWS Certification In Gurgaon https://www.bestforlearners.com/course/gurgaon/aws-training-institute-in-gurgaon
ReplyDeleteWant to develop virtual classroom mobile app based on SaaS or virtual classroom software? Arka Softwares offers virtual classroom development solutions with features like video streaming. Hire eLearning app development company that provides most consistent, skilled and cost-efficient services.
ReplyDeleteNice blog, Your efforts were commendable, i really appreciate your work, keep going on. For more details do not forget to visit on this link Training institutes in abu dhabi
ReplyDeleteAI assists in every area of our lives, whether we’re trying to read our emails, get driving directions on Google maps, get music or movie recommendations on Spotify, Netflix or YouTube, to Photo editors on smartphones, to Tesla’s Self-Driving cars, to intelligent assistants such as Siri, Alexa, Cortana etc. and the list is endless of how the world is constantly interacting with AI.
ReplyDeletecoding websites for kids
Good information you shared. keep posting.
ReplyDeletedata scientist online course
Hi, do You know antyhing regarding computer speakers and dell computers or apple computers? If not check my blog plymouth computer repair. If You are looking for dog Dominos menu is without question great. I would suggest anyone to purchase a Dominos Pizza menu instantaneously!! Dominos is delivering the best pizza of the world!!
ReplyDeleteWho first sold me on this feeling to freely allow something that provides an unique solution for at that time?
Automatic Screw Feeder Machine
Thanks for sharing information.its very useful information with us.
ReplyDeleteRR technosoft offering DevOps training in hyderabad.RR Technosoft offers DevOps training in Hyderabad. Get trained by 15+ years of real-time IT experience, 4+ years of DevOps & AWS experience. RR Technosoft is one of the trusted institutes for DevOps Online training in Hyderabad.
Well-written and informative blog. I appreciated your effort in this blog. I hope you post some more blogs again quickly.
ReplyDeleteAI Patasala-Machine Learning Course
AI Patasala-Artificial Intelligence Course
Good information,Thank you for sharing.RR Technosoft offering Devops course in Hyderabad .RR technosoft offers DevOps Course in Hyderabad . Get trained by 15+ years of real-time IT experience, 4+ years of DevOps & AWS experience. RR Technosoft is one of the trusted institutes for DevOps classroom & Online courses in Hyderabad.Get more information.
ReplyDeleteCall us : 7680001943
Really Nice Information It's Very Helpful All courses Checkout Here.
ReplyDeletemachine learning course in aurangabad
Hire professional web development companies in India offer excellent service at an affordable range.
ReplyDeleteAppreciate you sharing, great article. Much thanks again. Really Cool.
ReplyDeletepython training
angular js training
selenium trainings
https://physicsafterengineering.blogspot.com/2019/06/make-most-out-of-your-undergraduate-days.html
ReplyDeleteThanks a lot for sharing your great help full blog posting for all of us students. And I got this post and read properly it's very interesting and valuable for student.
ReplyDeleteStudy Abroad - Services Plan
Nice blog! Your blog is very informative. HeyCleo is a magnificent AI-based English learning app that allows you to grasp different concepts of English at your own pace. You can select a virtual teacher and get started with your learning journey.
ReplyDeleteAwesome article, it was exceptionally helpful! I simply began in this and I'm becoming more acquainted with it better! Cheers, keep doing awesome! AI Sex Robots
ReplyDeleteYou made such an interesting piece to read, giving every subject enlightenment for us to gain knowledge. Thanks for sharing the such information with us to read this... AI Sex Robot
ReplyDeleteThanks for Sharing this Information. Machine Learning Training in Gurgaon
ReplyDeleteGood information through the blog. Highly appreciable. Read it once if you are unclear of the basic concepts.
ReplyDeleteProfessional course certification
This is actually good to read content of this blog. A is very general and huge knowledgeable platform has been known by this blog. I in reality appreciate this blog to have such kind of educational knowledge. Best School in Mansarovar Jaipur
ReplyDeleteHow helpful this information loved it, we have searched for the best place for abroad study in Hyderabad. Then I got this blog post really they provide amazing consultants.
ReplyDeleteAbroad Consultancy in Vizag
Abroad Study in Vijayawada
Abroad Study Services
How helpful this information loved it, we have searched for the best place for abroad study in Hyderabad. Then I got this blog post really they provide amazing consultants.
ReplyDeleteAbroad Consultancy in Vizag
Abroad Study in Vijayawada
Abroad Study Services
Abroad Study in Hyderabad
useful info Business Analytics Course in Ranchi
ReplyDeleteNice posr. The blog has information related to machine learning and neural networks.
ReplyDeleteArtificial Intelligence solutions
Machine Learning Institute in Delhi
ReplyDeletethanks for share
ReplyDeletedata scientist course in pune
thanks for share
ReplyDeletebest data science course online
Our Data Science course in Hyderabad will also help in seeking the highest paid job as we assist individuals for career advancement and transformation. We carefully curate the course curriculum to ensure that the individual is taught the advanced concepts of data science. This helps them in solving any challenge that occurs. Along with that, we also make students work on real case studies and use-cases derived.
ReplyDeletedata science course in hyderabad
data science training in hyderabad
RR Technosoft offering Best DevOps Training in Hyderabad.Get trained by 15+ years of real-time IT experience, 4+ years of DevOps & AWS experience. RR Technosoft is one of the trusted institutes for DevOps classroom & Online training.For more information contact (+91)-7680001943.
ReplyDeleteCertificate Course in Machine Learning on Cloud
ReplyDeleteCertificate Course in Machine Learning on Cloud
ReplyDeleteI have read your blog its very attractive and impressive. it's easy to read. i agree with your machine learning course Details.
ReplyDeleteInnomatics Research Labs is collaborated with JAIN (Deemed-to-be University) and offering the Online MBA in Artificial Intelligence & Business Intelligence Program. It is a sublime program of getting an MBA degree from one of the best renowned university – JAIN University and an IBM certification program in Data Science, Artificial Intelligence, and Business Intelligence from Innomatics Research Labs in collaboration with Royal Society London.
ReplyDeleteOnline MBA in Artificial intelligence from Jain University
Thankyou for this detailed and useful information about machine learning.
ReplyDeleteVisit us:Data Science Course in Trichur
nice blog post information.
ReplyDeletecheck out:Data Analytics Course in Rohtak
thank you for the information. Visit us: Data Science Course in ludhiana
ReplyDeleteInnomatics Research Labs is collaborated with JAIN (Deemed-to-be University) and offering the Online MBA in Artificial Intelligence & Business Intelligence Program. It is a sublime program of getting an MBA degree from one of the best renowned university – JAIN University and an IBM certification program in Data Science, Artificial Intelligence, and Business Intelligence from Innomatics Research Labs in collaboration with Royal Society London.
ReplyDeleteOnline MBA in Artificial intelligence from Jain University
Thanks for more information, visit us: Data Analytics Course in Gwalior
ReplyDeleteThnx for sharing this useful information.
ReplyDeleteData Science Course in Shimoga
ReplyDeleteabinitio training
spark training
scala training
azure devops training
app v training
sccm training
Google Ads (Google Adwords) is an online platform from Google that will help businesses run ads on Google search and other partner websites. The major advantage of Google Ads is that it can give you instant traffic. The moment your ad gets approved your Ad will start appearing on Google and its partnered websites so it can drive instant traffic to your website.
ReplyDeleteyour blog always comes up with valuable information keep it up
ReplyDeleteIm obliged for the blog article.Thanks Again. Awesome.
ReplyDeleteMuleSoft training
python training
Angular js training
selenium trainings
sql server dba training
Become an expert Customer Service Manager Courses Online with MindCypress’s online courses. Enhance your skills and understand the importance of delivering satisfactory services and products to your customers.
ReplyDeleteMachine Learning is becoming most famous technology in recent days which allows software applications to become accurate in predicting outcomes.
ReplyDeleteLooking for Digital Transformation Company in Dubai? Reach Way2Smile.
ReplyDeleteGreat Article, Thank you for sharing such an impressive and useful post
Social Media Management
Natural Language Processing