This week, we will talk about how to identify the peaks from a time series. For example, the 2nd figure below. How do we find out all the location of the peaks? let's play with the coastal water level data from NOAA. You can choose the station you like. I choose the one at San Francisco, station - 9414290, the latitude and longitude of this station are 37.806331634, -122.465919494, you can see the station location on the following map:
I just downloaded the first 12 days in 2018, you can also quickly download this data from my repo here. You can find the notebook on Qingkai's Github written in Python3.
Let's first plot the time series data for the water level at this location.
import matplotlib.pyplot as plt
import pandas as pd
plt.style.use('seaborn-poster')
%matplotlib inlinedf_water_level = pd.read_csv('./data/9414290_20180101to20181231.csv', skiprows = 10, delimiter='\t', names=['datetime', 'water_level'])
df_water_level['datetime'] = pd.to_datetime(df_water_level['datetime'])
df_water_level = df_water_level.set_index('datetime')plt.figure(figsize = (14, 8))
plt.plot_date(df_water_level.index, df_water_level.water_level, 'b-', linewidth = 2)
plt.xlabel('Datetime')
plt.ylabel('Water level (m)')
plt.show()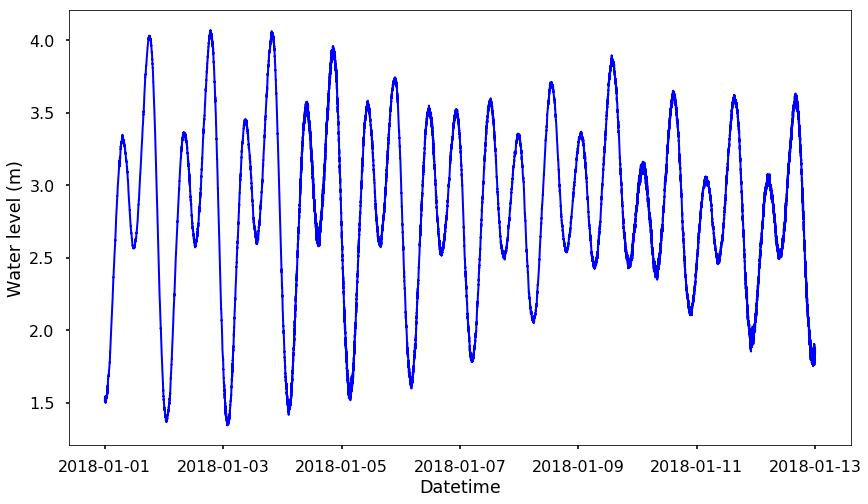
Let's find the peak
Since version 1.1.0, scipy added in the new function find_peaks that gives you an easy way to find peaks from a data series. It has various arguments that you can control how you want to identify the peaks. You can find more details and more advanced examples here. The two arguments I found really useful and easy to use is the height and distance. The height argument is the required height of peaks. And the distance is the required minimal horizontal distance in samples between neighboring peaks. Let's use see more in the following example
import scipy.signal
Here, we can see from the figure that all the positive peaks are roughly higher than 2.5, therefore, we set height = 2.5, which means that it will detect the peaks that higher than 2.5. Then for the distance parameter, I usually play with different numbers and see which one gives me the best result, for this case, I found distance = 500 is fine.
# find all the peaks that associated with the positive peaks
peaks_positive, _ = scipy.signal.find_peaks(df_water_level.water_level, height = 2.5, threshold = None, distance=500)plt.figure(figsize = (14, 8))
plt.plot_date(df_water_level.index, df_water_level.water_level, 'b-', linewidth = 2)
plt.plot_date(df_water_level.index[peaks_positive], df_water_level.water_level[peaks_positive], 'ro', label = 'positive peaks')
plt.xlabel('Datetime')
plt.ylabel('Water level (m)')
plt.legend(loc = 4)
plt.show()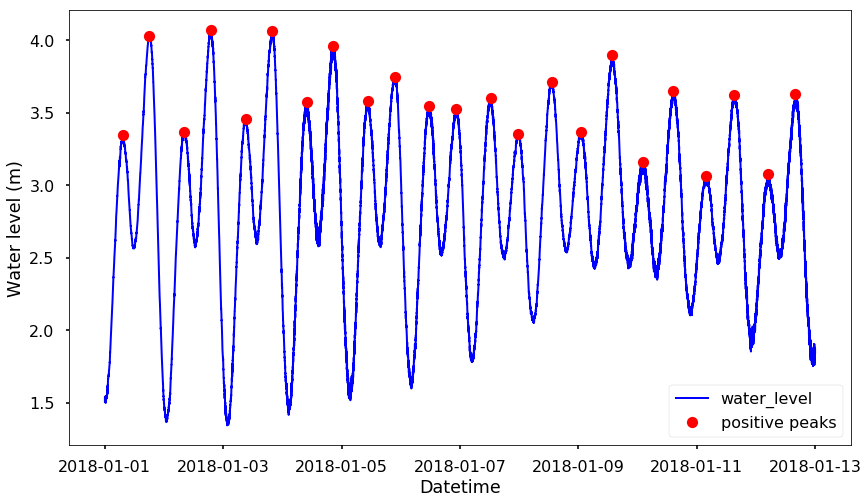
One thing is that, this find_peaks function can only detect the 'real' peaks, but not the troughs. You can see none of the troughs in the above figure were identified. One simple solution is that, we flip the data so that all the troughs become peaks. And now we could identify all the peaks and troughs.
# find all the peaks that associated with the negative peaks
peaks_negative, _ = scipy.signal.find_peaks(-df_water_level.water_level, height = -3, threshold = None, distance=500)plt.figure(figsize = (14, 8))
plt.plot_date(df_water_level.index, df_water_level.water_level, 'b-', linewidth = 2)
plt.plot_date(df_water_level.index[peaks_positive], df_water_level.water_level[peaks_positive], 'ro', label = 'positive peaks')
plt.plot_date(df_water_level.index[peaks_negative], df_water_level.water_level[peaks_negative], 'go', label = 'negative peaks')
plt.xlabel('Datetime')
plt.ylabel('Water level (m)')
plt.legend(loc = 4)
plt.show()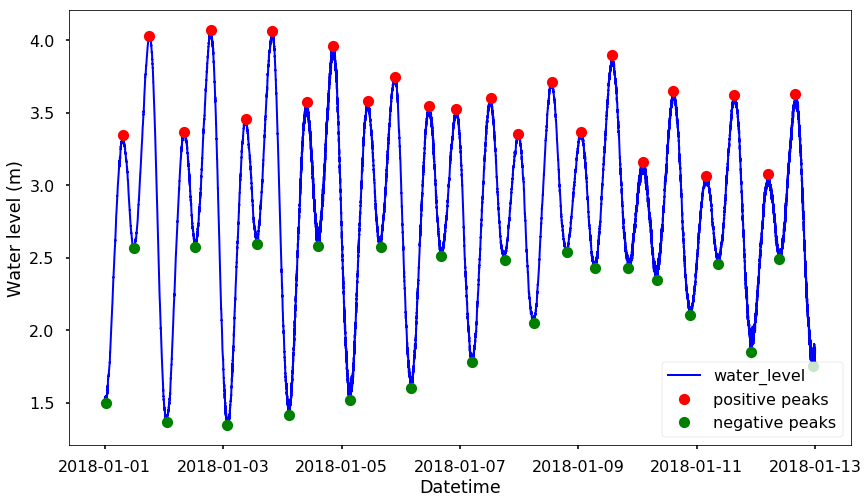
Of course, there are various arguments that we could use to filter out the unwanted peaks, see the documentation for more details.
This is a great article, it gave lots of information. It is extremely helpful for all. Keep sharing.
ReplyDeletePython Classes in Chennai
Python Training Institute in Chennai
ccna Training in Chennai
ccna course in Chennai
R Training in Chennai
R Programming Training in Chennai
Python Training in T Nagar
Python Training in OMR
Thank you so much for your blog. It helped me allott
ReplyDeleteThanks for this it was very helpful for me!
ReplyDeleteAm here to testify what this great spell caster done for me. i never believe in spell casting, until when i was was tempted to try it. i and my wife have been having a lot of problem living together, she will always not make me happy because she have fallen in love with another man outside our relationship, i tried my best to make sure that my wife leave this woman but the more i talk to her the more she makes me fell sad, so my marriage is now leading to divorce because she no longer gives me attention. so with all this pain and agony, i decided to contact this spell caster to see if things can work out between me and my wife again. this spell caster who was a man told me that my wife is really under a great spell that she have been charm by some magic, so he told me that he was going to make all things normal back. he did the spell on my wife and after 5 days my wife changed completely she even apologize with the way she treated me that she was not her self, i really thank this man his name is Dr ose he have bring back my wife back to me i want you all to contact him who are having any problem related to marriage issue and relationship problem he will solve it for you. his email is oseremenspelltemple@gmail.com he is a man and his great. wish you good time.
ReplyDeleteHe cast spells for different purposes like
(1) If you want your ex back.
(2) if you always have bad dream
(3) You want to be promoted in your office.
(4) You want women/men to run after you.
(5) If you want a child.
(6) You want to be rich.
(7) You want to tie your husband/wife to be yours forever.
(8) If you need financial assistance.
(9) HIV/AIDS CURE
(10) is the only answer to that your problem of winning the lottery
Contact him today on oseremenspelltemple@gmail.com or whatsapp him on +2348136482342
Five weeks ago my boyfriend broke up with me. It all started when i went to summer camp i was trying to contact him but it was not going through. So when I came back from camp I saw him with a young lady kissing in his bed room, I was frustrated and it gave me a sleepless night. I thought he will come back to apologies but he didn't come for almost three week i was really hurt but i thank Dr.Azuka for all he did i met Dr.Azuka during my search at the internet i decided to contact him on his email dr.azukasolutionhome@gmail.com he brought my boyfriend back to me just within 48 hours i am really happy. What’s app contact : +44 7520 636249
ReplyDeletePOWERFUL LOVE SPELL CASTER WITH EFFECTIVE RESULT EMAIL DR GREAT AT INFINITYLOVESPELL@GMAIL.COM OR WHATSAPP HIM +2348118829899
ReplyDeleteOMG!! This is certainly a shocking and a genuine Testimony..I visited a forum here on the internet on the 15TH OF MAY 2021, And i saw a marvelous testimony of this powerful and great spell caster called DR GREAT on the forum..I never believed it, because i never heard nor learnt anything about magic before.. Not a soul would have been able to influence me about magical spells, not until DR GREAT did it for me and restored my marriage of 8 years and brought my spouse back to me in the same 24 hours just as i read on the internet..i was truly astonished and shocked when my husband knelt down begging for forgiveness and for me to accept him back.. I am really short of expressions, and i don't know how much to convey my appreciation to you DR GREAT you are a God sent to me and my entire family.. And now i am a joyful woman once again.. Email Dr Great at
infinitylovespell@gmail.com or infinitylovespell@yahoo.com
Add him up on WhatsApp +2348118829899
BLOG http://infinitylovespell1.blogspot.com
My name is Tom cam!!! i am very grateful sharing this great testimonies with you all, The best thing that has ever happened in my life, is how i worn the Powerball lottery. I do believe that someday i will win the Powerball lottery. finally my dreams came through when i contacted Dr. OSE and tell him i needed the lottery winning special numbers cause i have come a long way spending money on ticket just to make sure i win. But i never knew that winning was so easy with the help of Dr. OSE, until the day i meant the spell caster testimony online, which a lot of people has talked about that he is very powerful and has great powers in casting lottery spell, so i decided to give it a try. I emailed Dr. OSE and he did a spell and gave me the winning lottery special numbers 62, and co-incidentally I have be playing this same number for the past 23years without any winning, But believe me when I play the special number 62 this time and the draws were out i was the mega winner because the special 62 matched all five white-ball numbers as well as the Powerball, in the April 4 drawing to win the $70 million jackpot prize...… Dr. OSE, truly you are the best, with Dr. OSE you can will millions of money through lottery. i am a living testimony and so very happy i meant him, and i will forever be grateful to him...… you can Email him for your own winning special lottery numbers now oseremenspelltemple@gmail.com OR WHATSAPP him +2348136482342
ReplyDeleteI've gotten back with my ex boyfriend with the help of Dr.jumba, the best spell caster online and I highly recommend Dr.jumba to anyone in need of help!.. I want to testify of how i got back my boyfriend after he breakup with me, we have been together for 3 years, recently i found out my boyfriend was having an affair with another Girl, when i confronted him, it led to quarrels and he finally broke up with me, i tried all i could to get him back but all to no avail until i saw a post in a relationship forum about a spell caster who helps people get back their lost love through Love spell, at first i doubted it but decided to give it a try, when i contacted this spell caster via his email, and he told me what to do and i did it, Then he did a Love spell for me. 28 hours later, my boyfriend really called me and told me that he misses me so much, So Amazing!! So that was how he came back that same day, with lots of love and joy, and he apologized for his mistake, and for the pain he caused me. Then from that day, our relationship was now stronger than how it were before, All thanks to DR.Jumba. he is so powerful and i decided to share my story on the Internet that Dr.Jumba real and powerful spell caster who i will always pray to live long to help his children in the time of trouble, if you are here and you need your Ex back or your husband moved to another woman, do not cry anymore, contact this powerful spell caster now. Here’s his contact: Email him at: wiccalovespelltools@gmail.com or wiccalovespelltools@yahoo.com, you can also call him or add him on WhatsApp: +19085174108 check out his website : drjumbaspellhome.wordpress.com
ReplyDeleteThank you Dr Jumba for your genuine spells. This is really incredible, and I have never experienced anything like this in my life. Before I came in contact with Dr Jumba, I have tried every possible means that I could to get my husband back, but I actually came to realize that nothing was working out for me, and my husband had developed a lot of hatred for me.. I thought there was no hope of reuniting with my husband until my friend told me about dr jumba and she gave me dr jumba website i googled it and read good reviews about Dr Jumba work , I decided to give it a try and I did everything that he instructed me and I trusted in him and followed his instructions just as he had guaranteed me in 24 hours, and that was exactly when my husband called me and ask for forgiveness that he his on his way to my house .. We are good more than ever. Everything looks perfect and so natural! Thank you so much for your authentic and indisputable spells. Thank you Dr Jumba for your help. If you need help in your marriage or broken relationship, contact Dr Jumba right now for urgent help Email: wiccalovespelltools@gmail.com OR wiccalovelovespelltools@yahoo.com View his websitehttps://drjumbaspellhome.wordpress.com/ Call/WhatsApp him: +19085174108
ReplyDeleteI want to testify about TD Ameritrade who helped me invest my bitcoin and made me who I am today, I never believe in investing in bitcoin until I met TD Ameritrade. I saw so many testimonies about him helping people to invest their bitcoin. I decide to contact him and invested $500 and, after 72 hours, I get my $ 5,000 profit in my bitcoin wallet. Since I invested with them and I always receive my profit without delay, so if you want to invest your bitcoin, TD Ameritrade is the best deal with which you can invest and make profit is a guarantee. So, if you want to invest, just contact him and he will guide you on how to start your investment. Email: tdameritrade077@gmail.com
ReplyDeletebest spell caster 2020 is Dr Twaha the great wizard from African I want to use this medium to thank him for bringing my ex lover back to me he only told me to provide the items needed for the spell and which I did and he told me that after he got the items in 24 hours I will start seeing the result and truly is a man of his words,,, contact him today and get your problem solve he can help you with any problems …. Email him.
ReplyDelete(drlregbeyen10000@gmail.com
you can also reach him on WhatsApp +2349038518881
My name is Dawn Drury I had struggle relationship with my husband in the past which led to divorce with my first husband. The memories of my husband was still in me and i realized how much i loved him and have missed him. I wept bitterly that night thinking i have lost the man that i have had so much love for. I asked for advise on what to do and a friend of mine gave me a contact of DR JOHN SOCO , i consulted him and to his very best with his powerful spells he helped me with a reunion marriage love spell to returned my ex husband back to me, in just 3 days i had encounter with a spiritual reunion prayers with DR JOHN SOCO everything turn around for good in my life, I am now happily living with my husband again and sort out the divorce issues. I testify here today that DR JOHN SOCO is powerful it can resolve all problem in a broken relationship with love once. contact him for solutions to any problems. email him at: drjohnsoco @ gmail.com You can also WhatsApp him on +1 706 871 4571 .
ReplyDeleteAll thanks to Mr Anderson for helping with my profits and making my fifth withdrawal possible. I'm here to share an amazing life changing opportunity with you. its called Bitcoin / Forex trading options. it is a highly lucrative business which can earn you as much as $2,570 in a week from an initial investment of just $200. I am living proof of this great business opportunity. If anyone is interested in trading on bitcoin or any cryptocurrency and want a successful trade without losing notify Mr Anderson now.Whatsapp: (+447883246472 )
ReplyDeleteEmail: tdameritrade077@gmail.com
Hello everyone, my name is Drenzy Xedusa I am so overwhelmed with joy all thanks to Dr Ojogun spell. my husband left me for another woman few years back and I was very devastated cause I never did anything wrong to him, I was left with my two kid and a job that pays little.i was almost giving up until I saw a testimony online about Dr Ojogun and I decided to contact him.i explained my problem to him and he assured me I'll see a positive result after 24hurs, surprisingly my husband came back the day after the spell begging me to forgive him and promised to never leave. My husband has been back for 6 months now and we've never had any issues, am glad I didn't doubt Dr Ojogun cause he sure can solve any problems with fast relief you can also contact him for help now Email: ( drojogunspellcaster@gmail.com ) Page Link is https://www.facebook.com/pg/drojogunspell/ or WhatsApp: + 2348161638124)
ReplyDeleteThis is true. Natural herbs have cured so many illnesses that drugs and injections can’t cure. I've seen the great importance of natural herbs and the wonderful work they have done in people's lives. I read people's testimonies online on how they were cured of HERPES, HIV, diabetics etc by Dr Akhigbe herbal medicine, so I decided to contact the doctor because I know nature has the power to heal anything. I was diagnosed with HPV and Herpes for the past 3 years but Dr Akhigbe cured me with his herbs and i referred my aunt and her husband to him immediately because they were both suffering from Herpes but to God be the glory, they were cured too .I know is hard to believe but am a living testimony. There is no harm in trying herbs, visits to Contact Dr Akhigbe: Email: Drakhigbeherbalhome5@gmail.com,WhatsApp number: +2349021374574..
ReplyDeleteAsset Recovery and Crypto Fraud, Top Crypto Recovery Professional Contact OPTIMISTIC HACKER GAIUS
ReplyDeleteOPTIMISTIC HACKER GAIUS is here to assist you in getting your money back and facing justice for the wrongdoing you have endured.
After being a victim of a fraudulent internet broker, do you feel lost and hopeless? OPTIMISTIC HACKER GAIUS is aware of the annoyance and rage that accompany being conned. To assist you get your money back and move on with your life, they are dedicated to giving you a prompt and efficient solution.
Visit Website; optimistichackergaius.c o m
Mail.... support@optimistichackergaius.com
WhatsAp....+44 737 674 0569
Great insights in this blog! I’ve always struggled with managing tight deadlines and complex financial topics during my course. At one point, I had to seek finance assignment help online just to keep up. It made a big difference in both my understanding and my grades. Posts like this really highlight how valuable expert academic support can be. Keep sharing such helpful content for students navigating tough academic paths!
ReplyDeleteThank you Dr Oseremen for what you have done for me. I am so grateful my lover is back to me and we are now living happy together. And also he can also cure you from any infection you're diagnosed with trust me,You can get in contact with dr Oseremen for any kind of spiritual problems and needs help with getting your health back And you can get in touch with him viaWhatsApp: (+2348153622587)Emall: droseremen005@gmail. com
ReplyDeleteFor many years, my husband and I struggled with the pain of not being able to have a child. We tried many treatments and prayed for a miracle, but nothing worked. When I heard about Dr. Alaska, I decided to reach out with faith. After following the spiritual guidance he gave us, the unbelievable happened I finally became pregnant. Today, we are blessed with a beautiful baby, and our home is filled with happiness. Another amazing blessing came when Dr. Alaska shared lucky numbers with my husband to try in a lottery game. My husband decided to play them, and to our surprise, he won a huge amount of money. It felt like our lives changed completely in the most wonderful way. I reached him on WhatsApp: +233277283626, but if you don’t have WhatsApp you can also email him via alaskaspellcaster44@gmail.com
ReplyDelete