The material is based on my workshop at Berkeley - Machine learning with scikit-learn. I convert it here so that there will be more explanation. Note that, the code is written using Python 3.6. It is better to read the slides I have first, which you can find it here. You can find the notebook on Qingkai's Github.
This week, we will talk how to use scikit-learn for regression problems. Instead of simple linear regression, we will do a regression problem on a non-linear dataset that we generate by ourselves.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
plt.style.use('seaborn-poster')
%matplotlib inlineGenerate data
Let's first generate a toy dataset that we will use a Random Forest model to fit it. We generate a periodical dataset using two sine wave with different period, and then add some noise to it. It can be visualized in the following figure:
np.random.seed(0)
x = 10 * np.random.rand(100)
def model(x, sigma=0.3):
fast_oscillation = np.sin(5 * x)
slow_oscillation = np.sin(0.5 * x)
noise = sigma * np.random.randn(len(x))
return slow_oscillation + fast_oscillation + noise
plt.figure(figsize = (12,10))
y = model(x)
plt.errorbar(x, y, 0.3, fmt='o')<Container object of 3 artists>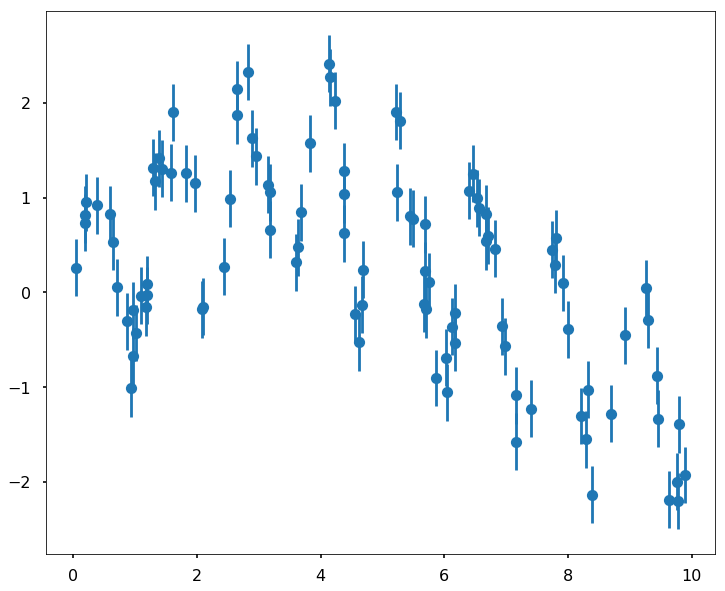
Fit a Random Forest Model
We will use random forest, a method that based on decision trees. The idea actually is very simple, if we look at the following figure the blue line, we just ask some questions like this: if my data is between 0.5 and 3.3, then my target value will be 0.7. We can think the regression line is made up of many segments of flat lines, therefore, we see many step-like lines on the following graph.

In the following, we fit a random forest model with 100 trees (the more trees we use, the more flexible the model is, that we can model wiggly part), and all the other parameters are using the default.
xfit = np.linspace(0, 10, 1000)
# fit the model and get the estimation for each data points
yfit = RandomForestRegressor(100, random_state=42).fit(x[:, None], y).predict(xfit[:, None])
ytrue = model(xfit, 0)
plt.figure(figsize = (12,10))
plt.errorbar(x, y, 0.3, fmt='o')
plt.plot(xfit, yfit, '-r', label = 'predicted', zorder = 10)
plt.plot(xfit, ytrue, '-k', alpha=0.5, label = 'true model', zorder = 10)
plt.legend()<matplotlib.legend.Legend at 0x111c02f60>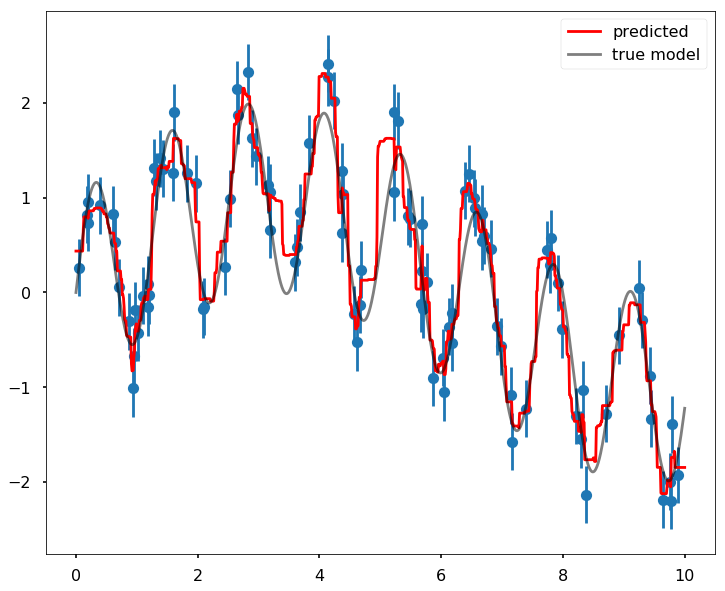
Print out the misfit using the mean squared error.
mse = mean_squared_error(ytrue, yfit)
print(mse)0.0869576380256Using ANN
We can also use ANN for regression as well, the difference will be at the activation function in the output layer. Instead of using some functions like tanh or sigmoid to squeenze the results to a range between 0 and 1, we can use some linear activation function to generate any results.
from sklearn.neural_network import MLPRegressormlp = MLPRegressor(hidden_layer_sizes=(200,200,200), max_iter = 2000, solver='lbfgs', \
alpha=0.01, activation = 'tanh', random_state = 8)
yfit = mlp.fit(x[:, None], y).predict(xfit[:, None])
plt.figure(figsize = (12,10))
plt.errorbar(x, y, 0.3, fmt='o')
plt.plot(xfit, yfit, '-r', label = 'predicted', zorder = 10)
plt.plot(xfit, ytrue, '-k', alpha=0.5, label = 'true model', zorder = 10)
plt.legend()<matplotlib.legend.Legend at 0x111e2a0f0>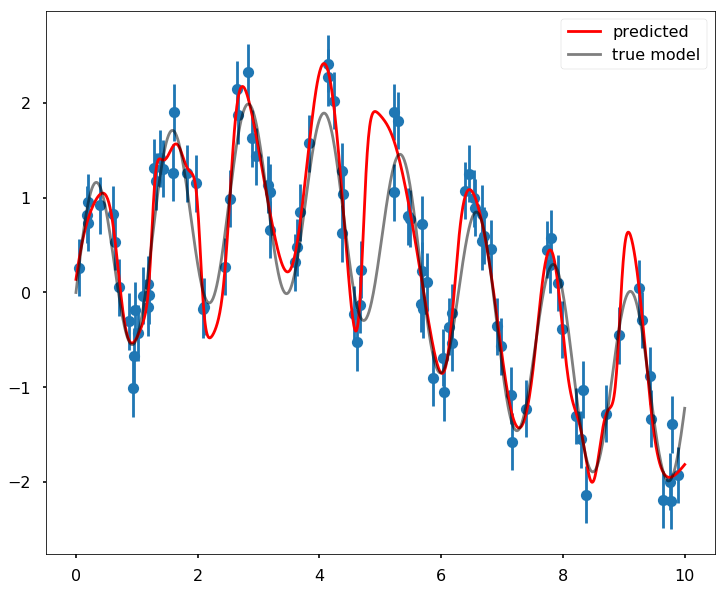
mse = mean_squared_error(ytrue, yfit)
print(mse)0.161981739823Using Support Vector Machine
The Support Vector Machine method we talked about in the previous notebook can also be used in regression. Instead of import svm, we import svr for regression probelm. The API is quite similar as the ones we introduced before, here is the quick regression using SVR.
from sklearn.svm import SVR
# define your model
svr = SVR(C=1000)
# get the estimation from the model
yfit = svr.fit(x[:, None], y).predict(xfit[:, None])
# plot the results as above
plt.figure(figsize = (12,10))
plt.errorbar(x, y, 0.3, fmt='o')
plt.plot(xfit, yfit, '-r', label = 'predicted', zorder = 10)
plt.plot(xfit, ytrue, '-k', alpha=0.5, label = 'true model', zorder = 10)
plt.legend()<matplotlib.legend.Legend at 0x115bdbb70>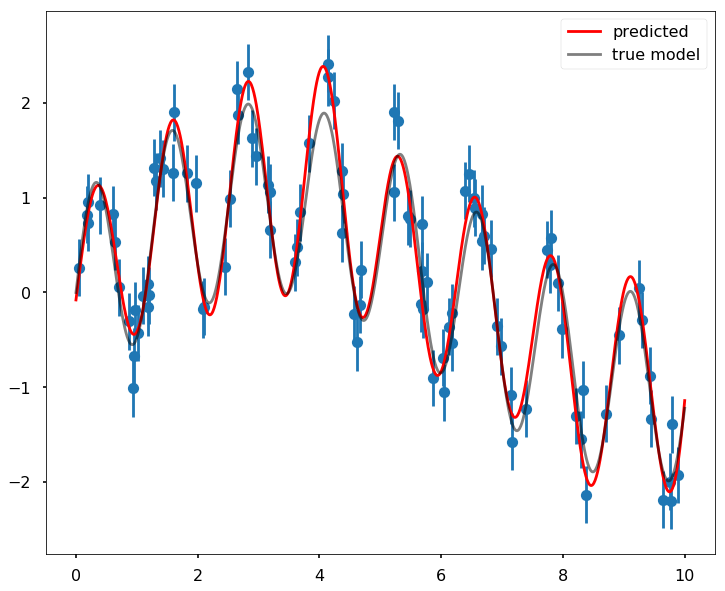
mse = mean_squared_error(ytrue, yfit)
print(mse)0.0289468172074
Nice informative blog.. Keep updating these types of informative updates regularly...Also Visit this site for Machine Learning with Python Training
ReplyDelete
ReplyDeleteIt is really a great work and the way in which u r sharing the knowledge is excellent.
Also Check out the : https://www.credosystemz.com/training-in-chennai/best-data-science-training-in-chennai/
Hello,
ReplyDeleteMachine Learning is a study that makes computers act without being explicitly programmed. It corresponds to a core sub-area of Artificial Intelligence. When exposed to new data, computer programs grow and develop by themselves. Machine Learning experts are widely contributing in making the software applications more scalable all over the world. Machine Learning training is available very simply in the present scenario and one can avail it to assure a career with tremendous growth. Currently, there are technologies that are helping businesses in this matter. One example is Machine Learning which is basically a form of Artificial intelligence. The primary aim of this approach is to enhance the software applications in every aspect.
Hello
ReplyDeleteI am realizing an app to predict stock market prices using scikit-learn
and MLPRegressor. My question in term of code, can we put in function
predict() to predict new values of price beyond my dataset? thank you for the tutorial
Good Blog
ReplyDeleteThanks For Sharing
Machine learning in Vijayawada
Nice informative blog.. Keep updating these types of informative updates regularly.
ReplyDeleteORACLE OSB Online Training
SAP WM Online Training
Angular JS Online Training
nice blog.
ReplyDeleteDataGuard Online Training
Devops Online Training
This is one awesome blog article. .
ReplyDeletePython Training in Gurgaon
Python Course in Gurgaon
Python Training institute in Gurgaon
Well! If you’re not in a position to customize employee payroll in Quickbooks which makes the list optimally, in QB and QB desktop, then read the description ahead. Here, you will get the determination of numerous type of information that which you’ve close at hand for assisting the setup process QuickBooks Payroll Support Phone Number
ReplyDeleteOur customer service executives have significant amounts of experience and so are sharp along with smart in finding out the particular cause QuickBooks Enterprise Support Phone Number solution each and every error that you could face.
ReplyDeleteQuickBooks Support Phone Number today’s scenario men and women have got really busy in their lives and work. They wish to grow and learn as many new things as they possibly can. This drive has initiated a feeling of awareness amongst individuals and so they find ways to invent choices for daily tasks.
ReplyDeleteOnly then, you will mend the problem confidently. Let’s have an instant feel probably the most frequent causes of data issues in QuickBooks support Phone Number.
ReplyDeleteRetail: The most time-consuming business type is retail. It takes lot of time and hard work. With QuickBooks Enterprise support Phone Number it becomes easy to manage the whole hassle of this type of business.
ReplyDeleteNot Even Small And Medium Company But Individuals Too Avail The Services Of QuickBooks Enterprise Tech Support. It Is Developed By Intuit Incorporation And Has Been Developing Its Standards Since Then.
ReplyDeleteQuickBooks Support Number today’s scenario individuals have got really busy within their lives and work. They would like to grow and learn as much new things as they possibly can. This drive has initiated a sense of awareness amongst individuals and therefore they find how to invent alternatives for daily tasks.
ReplyDeleteAt Intuit QuickBooks Support we focus on the principle of consumer satisfaction and our effort is directed to deliver a transparent and customer delight experience. A timely resolution into the minimum span is the targets of QuickBooks Toll-Free Pro-Advisors.
ReplyDeleteQuickBooks Support Phone Number professionals are terribly dedicated and might solve your entire issues without the fuss. In the event that you call, you might be greeted by our client service representative when taking all of your concern he/she will transfer your preference in to the involved department.
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteOur QuickBooks Payroll Customer Support Number has given a totally new direction when it comes to business, perhaps the beginners have adopted the right path creating improvements within their accounting fields.
ReplyDeleteLet’s speak about our QuickBooks Enterprise Number USA that'll be quite exciting for you personally all. The advanced QuickBooks Desktop App for QuickBooks Support can now act as an ERP system good for medium scale businesses. QuickBooks Desktop Enterprise is not alike to pro, premier & online versions. Capacity and capability can be the reason behind this.
ReplyDeleteYou merely need to build a straightforward charge less call on our QuickBooks Tech Support Number variety and rest leave on united states country. Without doubt, here you will find the unmatchable services by our supportive technical workers.
ReplyDeleteQuickBooks Customer Support Number discussing a great deal relating to this prodigious application, you might also be wondering that how can one carry forward the setup in addition to installation process for different operating systems.
ReplyDeleteIn the exact moment, QuickBooks Enterprise Support USA is the only amount that’s known globally for providing top-notch support services for many QuickBooks Enterprise Errors and Issues. The amount is live 24 hours and 7 days of this week and you may get help for QB Enterprise Errors in any given moment of this day.
ReplyDeleteSupport For QuickBooks shall help most of the folks. What business have you been having? Can it be raw material business? Would you cope with retail trade? Craftsmen also cope with your collection of revenue. Sometimes you may not forecast the precise budget.
ReplyDeleteGet prominent options for QuickBooks near you right away! Without any doubts, QuickBooks has revolutionized the process of doing accounting this is the core strength for small in addition to large-sized businesses. QuickBooks Support Phone Number is assisted by our customer support specialists who answr fully your call instantly and resolve all of your issues at that moment. It is a backing portal that authenticates the users of QuickBooks to perform its services in a user-friendly manner.
ReplyDeleteOn the off chance that you are through the USA and searching for the best tech help supplier in your nation, at that point you are welcome at our assistance work space. Alongside the QuickBooks error support, our QuickBooks Support Number provides the most extreme fulfillment to each and every certainly one of our clients.
ReplyDeleteConsist of a beautiful bunch of accounting versions, viz., QuickBooks Pro, QuickBooks Premier, QuickBooks Enterprise, QuickBooks POS, QuickBooks Mac, QuickBooks Tech Support Phone Number, and QuickBooks Payroll, QuickBooks has grown to become a dependable accounting software that one may tailor depending on your industry prerequisite.
ReplyDeletethe guidance of supremely talented and skilled support engineers that leave no stone unturned to land you of all of the errors that are part and parcel of QuickBooks. QuickBooks Support Phone Number has a lot to offer to its customers in order to manage every trouble that obstructs your projects.
ReplyDeletebeing a regular business person, working on professional accounting software, like QuickBooks, is clearly definitely not easy. Thus, users may have to face a range of issues and error messages when using the software; when you feel something went wrong along with your accounting software and may not discover a way out, you could get tech support team from our experts’ team, working day and night to correct any issues with respect to Intuit QuickBooks Support
ReplyDeleteQuickBooks Payroll Technical Support software has been developed for the sole purpose of enabling the individuals in creating customary as well as financial ties, letting them manage cash flow, update the billings and also the transactions. Since privacy is the governing case of concern, which means this software program is also effective in protecting important computer data from cyber threats plus it has an incredible feature of making file backups, in order to make their access easier. It is possible to send the files directly without converting them into portable file documents.
ReplyDeleteFor many for the company organizations, it really is and contains always been a challenging task to control the business accounts in a proper way by locating the appropriate solutions. The greatest solutions are imperative with regards to growth of the business enterprise enterprise. Therefore, QuickBooks is present for users world wide while the best tool to supply creative and innovative features for business account management to small and medium-sized business organizations. If you’re encountering any kind of QuickBooks’ related problem, you're going to get all of that problems solved simply by utilising the QuickBooks Technical Support Number.
ReplyDeleteThe lights regarding the device have already been switched off then it's likely that the error is within the HP Printer Support Phone Number power supply. To resolve the HP Laptop startup problem of the consumer has to disconnect the energy supply for a while and plug it back on.
ReplyDeletePlus the best, right and simple resolutions would be the most critical for the growth of everyone business. So because of this, QuickBooks Payroll Support Phone Number is just one of the great accounting software to easily manage all of those things.
ReplyDeleteAccountant: in the event that you handle accounts department of assorted companies or institutes etc. then QuickBooks Enterprise Support Number industry version is of great use.
ReplyDeleteNon-Profit: Running a non-profit organisation could be a troublesome task if not monitored properly.
You may already know the many benefits of QuickBooks Payroll Technical Support into your business. But as a business owner, you always expect that most your payroll or accounting related task run with no glitch.
ReplyDeleteWe ensure your calls do not get bounced. In case your calls are neglecting to connect with us at quickbook support contact number, you'll be able to also join our team by dropping an email without feeling shy. QuickBooks Tech Support Number customer service support will remain available even in the wee hours.
ReplyDeleteThe principal intent behind QuickBooks Support Phone Number would be to give you the technical help 24*7 so as with order in order to prevent wasting your productivity hours. It is completely a toll-free QuickBooks client Service variety that you won’t pay any call charges.
ReplyDeleteQuickBooks Payroll Support Number as well provides all possible help with the users to utilize it optimally. An individual who keeps connection with experts has the capacity to realize in regards to the latest updates.
ReplyDeleteQuickBooks has completely transformed the way people used to operate their business earlier. To get familiar with it, you should welcome this positive change. Supervisors at QuickBooks Support Phone Number have trained all of their executives to combat the issues in this software. Utilizing the introduction of modern tools and approaches to QuickBooks, you can test new techniques to carry out various business activities. Basically, this has automated several tasks that have been being done manually for a long time. There are lots of versions of QuickBooks and each one has a unique features.
ReplyDeleteGot stuck in QuickBooks errors? Not to worry now as we are here to solve all your queries. We at our Quickbooks Desktop Support Phone Number 1-800-986-4607 will assist you to get out of trouble.Avail the benefits of our services and run your business smoothly. Stay connected with us for more information.
ReplyDeleteThanks for sharing your valuable information and time.
ReplyDeleteMachine Learning Training in Delhi
In the banking transaction screen- click on one of the reported issues that are listed in the error message.
ReplyDeleteNow enter the “Registered name, registered email address” and submit it. If you would like to learn How To Fix Quickbooks Error 9999, you can continue reading this blog.
To get instant support for QuickBooks problems, dial QuickBooks Phone Number Pennsylvania +1-855-550-7546. Our team makes sure to provide you with the best-in-class technical service for QuickBooks at a reasonable rate.
ReplyDeleteFive weeks ago my boyfriend broke up with me. It all started when i went to summer camp i was trying to contact him but it was not going through. So when I came back from camp I saw him with a young lady kissing in his bed room, I was frustrated and it gave me a sleepless night. I thought he will come back to apologies but he didn't come for almost three week i was really hurt but i thank Dr.Azuka for all he did i met Dr.Azuka during my search at the internet i decided to contact him on his email dr.azukasolutionhome@gmail.com he brought my boyfriend back to me just within 48 hours i am really happy. What’s app contact : +44 7520 636249
ReplyDeleteشركة نقل عفش بالمدينة المنورة
ReplyDeleteشركة نقل اثاث بالرياض
شركة نقل عفش بالدمام
شركة نقل عفش بالطائف
ReplyDeletewhy are mountain bikes so expensive
Lovely information ! If you are looking Best Quickbooks Accounting Service Then you can reach us at
ReplyDeleteQuickbooks Customer Support Phone Number +1 855-977-3297 Elizabeth, NJ
It was a very good post We provide solutions for any Quickbooks issue if you have Quickbooks Related Queries then call at
ReplyDeleteQuickbooks Customer Service Phone Number+1 855-675-3194
Nice Blog, Good Content. you have any other questions about QuickBooks, just dial
ReplyDeletequickbooks customer service+18554287237
Very Good Blog !! If You Are using Quickbooks Software For mange your Business but sometimes You May Face many problems during Installation but Quickbooks also Offer best QuickBooks Customer Service team and call at +18556753194
ReplyDeleteThanks For Sharing Wonderful Information If you need help with your business, the best thing to do is contact a QuickBooks expert at
ReplyDeletequickbooks customer service+17735165910
Very Good Blog !! I Quickbooks is an accounting software that help businesses manage their finances and payments. If you need help, the QuickBooks customer service +1 347-982-0046 team is here for help you.
ReplyDeleteIf you are one of those who are looking for a reliable and affordable QuickBooks accounting software, then call at QuickBooks Customer Service +18557297482
ReplyDeleteThis post is really very helpful article We help you Any query for regarding Quickbooks issue if you need help then you can dial at t QuickBooks Customer Service +1 267-773-4333
ReplyDeleteQuickBooks is Simple and easy to use Software to help small business and have any issue with Software then do call us at
ReplyDeletequickbooks customer service: +1 347-982-0046